GR-MG: Leveraging Partially Annotated Data via Multi-Modal Goal-Conditioned Policy
Paper Supplementary Code Checkpoints
Abstract
The robotics community has consistently aimed to achieve generalizable robot manipulation with flexible natural language instructions. One primary challenge is that obtaining robot trajectories fully annotated with both actions and texts is time-consuming and labor-intensive. However, partially-annotated data, such as human activity videos without action labels and robot trajectories without text labels, are much easier to collect. Can we leverage these data to enhance the generalization capabilities of robots? In this paper, we propose GR-MG, a novel method which supports conditioning on a text instruction and a goal image. During training, GR-MG samples goal images from trajectories and conditions on both the text and the goal image or solely on the image when text is not available. During inference, where only the text is provided, GR-MG generates the goal image via a diffusion-based image-editing model and conditions on both the text and the generated image. This approach enables GR-MG to leverage large amounts of partially-annotated data while still use languages to flexibly specify tasks. To generate accurate goal images, we propose a novel progress-guided goal image generation model which injects task progress information into the generation process. In simulation experiments, GR-MG improves the average number of tasks completed in a row of 5 from 3.35 to 4.04. In real-robot experiments, GR-MG is able to perform 58 different tasks and improves the success rate from 68.7% to 78.1% and 44.4% to 60.6% in simple and generalization settings, respectively. It also outperforms comparing baseline methods in few-shot learning of novel skills.
GR-MG is a model designed to support multi-modal goals: a language and a goal image. It consists of two modules: a progress-guided goal image generation model and a multi-modal goal-conditioned policy. The goal image generation model generates a goal image based on the current observation, a language description of the task, and the task progress. The multi-modal goal-conditioned policy takes the generated goal image, the current observation, and the language instruction as inputs to predict the action trajectory, task progress, and future images. The task progress is subsequently fed into the goal image generation model. The task progress is initialized as zero at the beginning of a rollout.
Example Rollout
Below, we show a rollout example below. Specifically, the goal image generation model generates the goal image every n timesteps. The goal image indicates the state the robot should move towards according to the given language instruction.
Multi-Task Learning Experiments
GR-MG is able to perform 58 tasks, including both pick-and-place and non-pick-and-place manipulations.
Here are a few examples of challenging tasks that go beyond simple pick-and-place operations.
push the dragon fruit off the cutting board
rotate the bottle to the left
rotate the bottle to the right
cap the white mug
uncap the white mug
close the drawer
stack the bowls
flip cup upright
wipe the cutting board
Generalization Experiments
GR-MG showcases powerful generalization capability. We evaluate its performance in four different settings including Simple, Unseen Disctractor, Uneen Background, and Unseen Object. Below, we show example rollouts in generalization settings.
Robust to Different Object Poses
press the toaster switch
open the oven
Robust to Unseen Distractors
pick up the mandarin from the green plate & place the picked object on the table
pick up the red mug from the rack & place the picked object on the table
Robust to Unseen Backgrounds
pick up the red mug from the rack & place the picked object on the table
pick up the potato from the vegetable basket & place the picked object on the cutting board
pick up the eggplant from the green plate & place the picked object on the red plate
pick up the red mug from the rack & place the picked object on the table
pick up the potato from the vegetable basket & place the picked object on the cutting board
pick up the eggplant from the green plate & place the picked object on the red plate
Robust to Unseen Objects
pick up the tiger from the red plate & place the picked object on the green plate
pick up the red apple from the red plate & place the picked object on the green plate
pick up the while bottle from the red plate & place the picked object on the green plate
pick up the yellow bottle from the vegetable basket & place the picked object on the cutting board
pick up the banana from the vegetable basket & place the picked object on the cutting board
pick up the red apple from the vegetable basket & place the picked object on the cutting board
Quantitative Results
We evaluate the performance of GR-MG in a CALVIN benchmark and a real robot. For the CALVIN benchmark, we evaluate GR-MG on the ABC->D challenge. GR-MG outperforms all baselines. The advantage becomes even more pronounced when using only 10% of data with language and action labels. The results are presented in the following table.
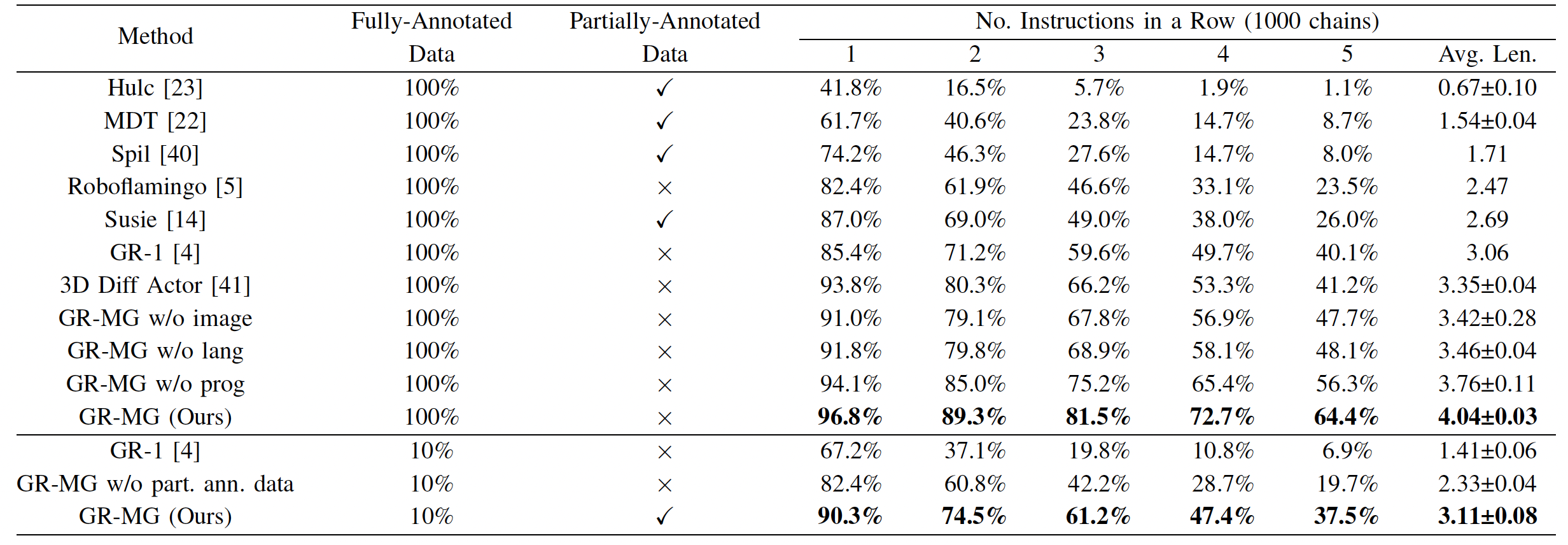
Results on CALVIN ABC->D
In real-robot experiments, we evaluate GR-MG in a simple setting as well as four challenging generalization settings. GR-MG consistently outperforms competitive baselines. Results are shown below.
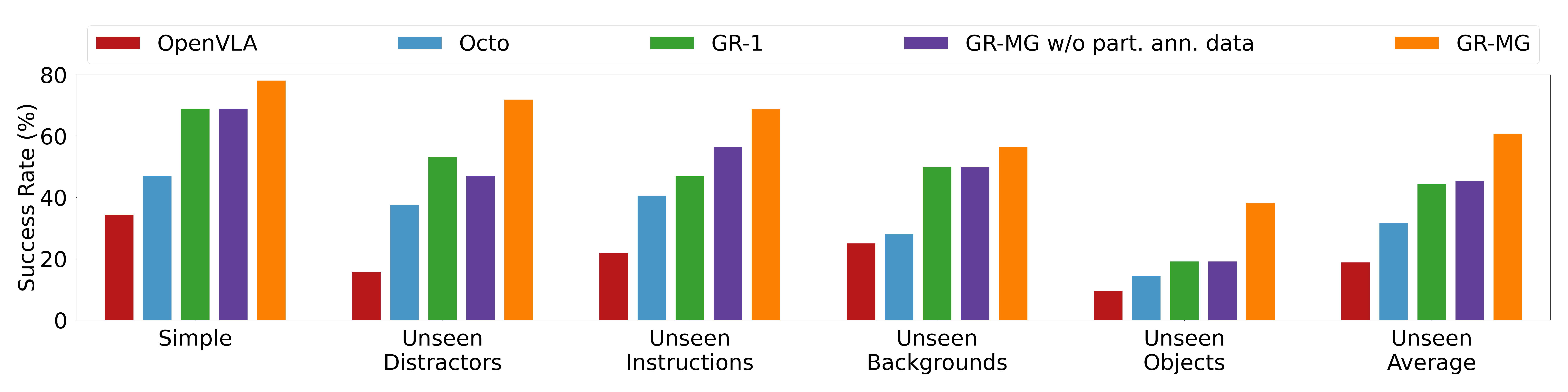
Success Rates of Real-Robot Experiments.
More details about our method and experimental settings can be found in our paper.
Citation
@article{li2025gr,
title={GR-MG: Leveraging Partially-Annotated Data Via Multi-Modal Goal-Conditioned Policy},
author={Li, Peiyan and Wu, Hongtao and Huang, Yan and Cheang, Chilam and Wang, Liang and Kong, Tao},
journal={IEEE Robotics and Automation Letters},
year={2025},
publisher={IEEE}
}